Loop Fallacy: Re-evaluating Performance Benchmarks.

Apart from the editor of your choice, one of the most common debates in CS circles almost always revolves around the programming language of one's choice. While the pragmatic (read: correct) answer to this question is to use the one that gets the job done most efficiently, a lot of online posts revolve around creating brute force methods to stress-test each language's efficiency and create charts such as the one below.
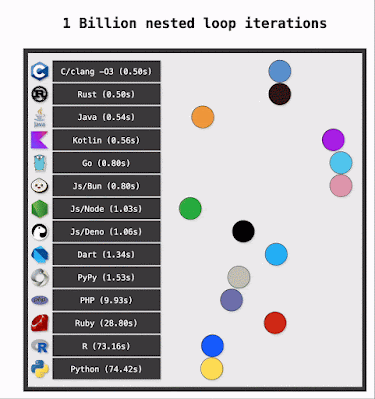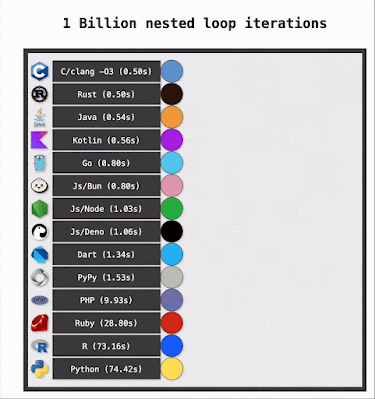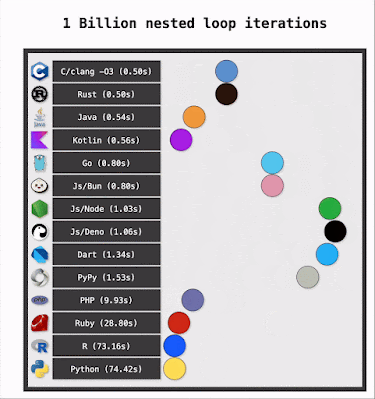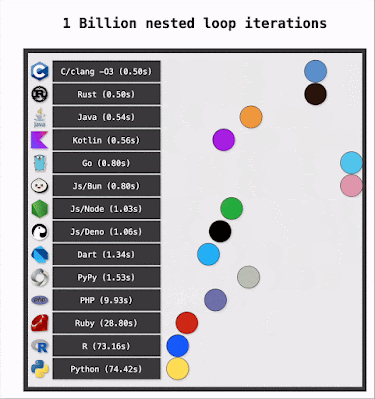
This is only one of the various interpretations I have seen that includes a brute force series of operations. In declaring the "best language to brute force for-loops", we ignore three fundamental aspects:
- The niche of the programming language
- The people and culture that surround the language
- The fact that these charts can easily be gamed by throwing extra hardware at the problem.
I am not saying that the hypothetical of "raw limitless power of a language" isn't a curiosity-sparking visualization that should be ignored. Quite the opposite: I actually extend my kudos to the author of this visualization as it sparks such debates and insights. I love people taking an interest in this topic. However, I only want to use this visualization as a stepping stone to delve deeper into the intricacies of compilers, and things that are not so obvious on first glance. I genuinely mean for this post to be as appreciative of the original author, and only using this post as a learning opportunity.
Context Matters
When we come across performance charts, like the one showing execution times for "1 Billion nested loop iterations," it's easy to draw quick conclusions. These kinds of benchmarks are quite common, and they often spark interesting discussions. However, to get a fuller understanding, it can be helpful to consider the many factors that might influence such results - details that often aren't immediately apparent.
One of the first things that often comes to mind with time-based benchmarks is the hardware itself. The chart shows C/clang completing the task in 0.50s and Python in 74.42s, but performance can vary significantly based on the CPU, RAM, and even the system's architecture. Without knowing the specifics of the test machine, it's hard to generalize the results. A different machine might yield a different spread of times. This is a key reason why time-based metrics can be tricky; they're often the one thing that can be "solved" by simply throwing more and/or different hardware at the problem.
Then there's the nature of the test. "1 Billion nested loop iterations" is a broad description. What exactly is happening inside those loops? An empty loop primarily tests the overhead of the looping construct itself. If there's an operation within the loop (like an arithmetic calculation, memory access, I/O operation, context switch, and so on), its nature will heavily influence the outcome. Different languages might handle these internal operations with varying degrees of efficiency based on their design.
For example, Python, designed for ease of use, has layers of abstraction (often built with underlying C implementations in CPython) that C++ doesn't. While this makes Python very approachable, it also means it might be doing more "behind the scenes" work for what appears to be the same simple loop. One might wonder if the benchmark accounted for this, for example, by ensuring C++ wasn't inadvertently advantaged by running "less" actual user-level code if Python's abstractions weren't somehow normalized in the comparison.
The specific versions and configurations of languages and compilers also play a role. The chart notes "C/clang -O3," indicating a specific compiler (Clang) and an optimization level (-O3). It's worth wondering if similar levels of optimization were applied or available for other compiled languages listed, like Rust or Java. For languages that use Just-In-Time (JIT) compilation, such as Java, Kotlin, or the JavaScript runtimes (Node, Deno, Bun), their performance can improve after initial "warm-up" runs as the JIT compiler optimizes hot paths. Do the reported times reflect this, or are they from a "cold" start? Different versions of, say, Python, R (with its Fortran backend), or PHP (whose performance can change significantly between versions due to backend rewrites, though the chart doesn't specify a PHP version) can also have performance differences.
Were the variables used in these loops simple 4-bit integers across all languages, or is it possible that higher-level languages might introduce their own metadata or perform implicit typecasting (e.g., to a float), leading to fundamentally different operations being timed? For languages with automatic garbage collection (like Java, Python, Go, Ruby, and JavaScript environments), the timing of a garbage collection cycle during the benchmark could potentially impact the measured execution time. It makes one consider if results are averaged over multiple runs to smooth out such variations, as the chart doesn't specify.
The chart also lists various JavaScript runtimes (Js/Bun, Js/Node, Js/Deno). This highlights an interesting point: we're often comparing not just the language (JavaScript) but also the sophisticated runtime environments built around them, which themselves are complex pieces of software often written in languages like C++ or Rust. The performance differences here could be as much about the runtime's engineering as about JavaScript itself.
Was the test strictly single-threaded? Some languages or their standard libraries might subtly leverage multi-core processors even for simple tasks, which would make it an uneven comparison if others are confined to a single thread. The chart doesn't offer clarity on this. These aren't trivial details; they are fundamental to any meaningful comparison, yet such charts often don't provide this full context.
Furthermore, without understanding the specifics of how these loops were written, we aren't probing too deep. For C, how much memory was allocated, and was it managed efficiently? For Python, how much of the measured time is attributable to the interpreter overhead versus the actual loop execution? These details are crucial. An inefficiently written C loop could theoretically perform worse than a highly optimized loop in a "slower" interpreted language, especially if the "slower" language's standard library implementation of a similar task is heavily optimized in C itself!
The very premise of "brute forcing for loops" as a measure of a language's worth might be an oversimplification for many real-world scenarios. Real-world applications are complex. They involve I/O operations, network requests, data structure manipulations, concurrency, and myriad other factors that are not captured by counting to a billion. Real-time performance, responsiveness under load, memory footprint, and developer productivity are often far more critical concerns than raw loop speed in isolation.
Thinking about these variables isn't meant to discredit benchmarks, but rather to encourage a more nuanced interpretation. Time-based metrics are one piece of the puzzle, but they can be influenced by many factors beyond the inherent "speed" of a language itself. Recognizing this can help us avoid oversimplifying the complex question of programming language efficiency and appreciate that there's often more to the story than the initial numbers might suggest.
One possible way to gauge programming language efficiency
So, how might one approach this differently? When I was exploring this for my thesis a couple years ago, the core idea was to sidestep the superficial, hardware-dependent metrics like raw execution time. Keep in mind, my thesis was only comparing C++ and Rust.
To get a more meaningful comparison between these languages, it felt necessary to delve right down to the low-level code their compilers produce. The aim was to create a comparison that was as "apples-to-apples" as possible, by trying to isolate the languages' inherent characteristics from the influence of specific hardware configurations or the transient state of a machine. This meant shifting the focus from simply timing how fast a program runs, a metric easily skewed by "throwing more hardware at the problem", to examining the actual computational work demanded by the compiled code. The hope was to understand how the distinct engineering philosophies and design choices of C++ and Rust manifest at a fundamental, architectural level (in this case, x86 Assembly), offering a glimpse into their baseline differences rather than just a snapshot of their speed on a particular setup.
The approach centered on analyzing the Assembly language output of the compilers. Both C++ (using Clang) and Rust (using rustc) were compiled down to x86 Assembly. Crucially, both Clang and rustc utilize the LLVM compiler infrastructure, which provides a more level playing field for comparison as they share a common backend for generating the LLVM IR, LLVM BC, and final machine instructions.
Once the Assembly code for identical programs (or as identical as possible given language paradigms) was generated, the next step was to trace their execution. This wasn't about timing how long they took to run, but rather meticulously recording every single Assembly instruction that the CPU executed from start to finish. This was achieved using the GNU Debugger (GDB) along with Python scripting to automate the tracing process (a toolchain I developed called tra86). GDB allows stepping through the program instruction by instruction, across multiple files, and logging each one. This creates a detailed trace file of the program's execution at the lowest human-readable level.
With these trace files, the core of the analysis involved calculating the total number of CPU clock cycles consumed by each program. This wasn't a direct measurement from the hardware, but rather an estimation based on established data (IA32 and IA64 Instruction Manuals) that details the typical number of clock cycles each specific x86 Assembly instruction takes to execute. By summing up the clock cycles for every instruction in the trace, we get a measure of the total computational effort. Other metrics, like cycles per instruction and the frequency of different types of assembly operations, were also derived to provide a more comprehensive picture.
The types of programs tested included common Linux command-line utilities (like ls, cat, cp) and a suite of self-written algorithms (such as Fibonacci sequence, linked list reversal, BFS, DFS, and sorting algorithms). This provided a mix of I/O-bound and CPU-bound tasks.

Thesis Poster: Presented at MassURC 2024
The key finding was that, when looking at cumulative clock cycles (our proxy for total CPU work), Rust generally performed more efficiently than C++ for the programs tested. For instance, in some tests, Rust was observed to be significantly faster (around 40% in terms of clock cycles) for the same logical task. While cycles per instruction sometimes varied, the overall reduction in total clock cycles indicated that Rust's compiler was often generating more efficient sequences of machine instructions for the given tasks, even with its strong emphasis on safety. This method, by focusing on the Assembly instructions and their associated clock cycles, attempts to circumvent the "throw more hardware at it" problem and provides a more nuanced insight into how different language compilers translate high-level code into low-level operations. It's a deeper dive than simply timing a billion loops. For a detailed exploration of this methodology and the complete findings, you can refer to the full thesis here.
Now, while I certainly don't claim to have a definitive, all-encompassing "real-world" solution to this complex problem of language comparison, the work in my thesis was an attempt to create a more apples-to-apples comparison at a fundamental level. It's important to remember, of course, that this is just one exploratory approach among many, and it certainly isn't without its own limitations. The reliance on GDB, for example, means that tracing can be incomplete if some system or header files weren't compiled with debugging flags, potentially skewing results for certain types of programs or language features. Estimating clock cycles from tables, while useful, is not as precise as direct hardware counters and doesn't account for all microarchitectural effects like caching or branch prediction penalties in real-time. Furthermore, the selection of test programs, while varied, can never be fully representative of all possible workloads. This method also primarily focuses on CPU-bound performance and doesn't deeply explore other critical aspects like memory management overhead in complex, long-running applications, or the impact of concurrent and parallel execution paradigms beyond what the GDB trace can capture. It's a step towards a more nuanced understanding, but the field of performance analysis is vast, and this work simply offers one perspective.
The Human Element: People and Culture
Beyond the technical specifications, every programming language fosters a community and a culture. This ecosystem includes its core developers, contributors, the richness of its libraries and frameworks, the quality of its documentation, and the availability of learning resources and community support.
For instance, the R language, while perhaps not topping "for loop" speed charts like the one discussed, has an unparalleled ecosystem for statistical computing and data visualization. This ecosystem is built by and for statisticians and data scientists, making it an incredibly effective tool for that domain.
The collaborative nature of open-source communities around languages like Python or Rust also significantly influences their evolution and adoption. Choosing a language can sometimes be as much about joining a supportive and knowledgeable community, with readily available solutions and help, as it is about the raw technical merits of the language itself.
Programming languages, much like everything else in the world, do not exist in a vacuum. Even looking at the chart above, it is ever so evident that each language here was made for their specific purposes. Python is a wonderfully versatile language, fantastic for scripting, data science, web development (think Django/Flask), and machine learning.
Its ease of use and extensive libraries make it a go-to for rapid prototyping and tasks where development speed trumps raw execution speed. It's also invaluable where we are trying to incorporate groups of people who are software developers second, using Python as a means to an end in their primary field.
You're not going to write microkernels in Python, nor would you typically choose Java for training deep neural networks from scratch if performance and low-level control are paramount. Similarly, languages like C and C++ excel in systems programming, game development, and high-performance computing precisely because they offer fine-grained memory control and compile closer to machine code. Even though Rust trumps C++ in various aspects, you would prefer C++ if you rely on the mature community that surrounds it and has written various packages and frameworks for the language. If you don't, you will recognize all the developer comfort, security, and speed that Rust brings to the table for your next project.
JavaScript, originally designed for client-side web scripting, now dominates front-end development and has a significant presence on the server-side with Node.js. Each has its domain, its strengths, and its trade-offs. These benchmarks often reveal little more than the fact that some languages have more levels of abstraction or compilation than others, which is often a deliberate design choice tied to their intended use case.
Efficiencies convey only one of the various aspects that goes into choosing a programming language for a task. There will always be a newer language around the corner that does something new. It is crucial to not get enamored with shiny object syndrome. Across all languages, the core concepts of programming remain the same. Use what gets the job done.
----
Cover Image: Boston Waterfront | Taken May 18, 2025

